출처 : http://it.plusblog.co.kr/221243790904

머신 러닝 알고리즘을 학습시킬 때 머신 러닝 모델이 얼마나 잘 학습되었는지 평가할 기준이 필요하다. 실제 데이터에 돌려보는 것도 좋지만 학습 단계에서 미리 평가할 수 있는 방법도 필요하다. 고객에게 배포되는 서비스에 섣부르게 알고리즘을 적용했다가 성능이 너무 안 좋게 나오면 문제가 될 수 있기 때문이다.
가장 흔하게 사용하는 방법은 수집된 데이터를 'Training DataSet(학습 데이터)'와 'Testing Dataset(테스트 데이터)'로 나누어 사용하는 것이다. 세분화 시키면 'Validation Dataset(검증 데이터)'로 하나 더 나눌 수 있다.
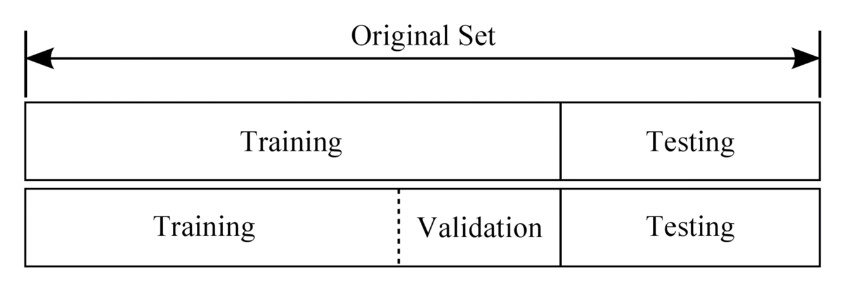
원래 가지고 있던 데이터인 'Original Set'을 'Training Set', 'Testing Set' 나아가서 'Validation Set'으로 나누어 사용하게 된다.
Training Set은 학습 시킬 Hypothesis의 파라미터들을 결정하는데 사용한다. 가중치와 Bias가 Gradient Descent 알고리즘에 의해서 결정된다. 학생으로 말하면 열심히 공부하는 과정에 사용되는 데이터가 된다.
Validation Set은 실제 학습된 모델을 평가하기 전에 Learning Rate와 Regulation에 사용했던 람다 값을 튜닝하는데 사용하게 된다. 학생으로 말하면 최종 시험을 보기 전 모의고사 문제를 풀어보는 것처럼 생각하면 된다.
Testing Set은 실제 학습된 모델을 평가하는데 사용되는 데이터다. 이 데이터를 이용해서 머신 러닝 알고리즘이 얼마나 잘 학습되었는지를 평가하게 된다.
Online Learning
학습해야 하는 데이터가 방대할 때, 그리고 학습에 사용되는 데이터가 꾸준히 입력될 때 'Online Learning'이라는 방법을 사용하기도 한다.

학습에 사용할 데이터가 굉장히 방대할 경우 데이터를 일정 단위로 나눠서 머신 러닝 모델을 학습시킨다. 첫 번째 데이터를 학습시키고, 두 번째 데이터를 학습 시키고, 세 번째 데이터를 학습 시키고... 여러 덩어리로 나눠진 데이터를 학습해나간다. 이때 학습은 Incremental 하게 이뤄지며 이전에 학습되었던 내용을 기반으로 학습하게 된다.
실시간으로 수집되는 데이터를 이용해 학습을 한다던가 대량의 데이터를 이용해서 학습할 경우 사용되는 방식이다.
머신 러닝 모델 평가 방법 (Accuracy, Precision, Recall, F1 Score)
이번 포스트에서 데이터 셋을 나눠서 학습에 사용되지 않은 데이터를 이용해 평가를 한다고 말했다. 그럼 어떤 모델이 얼마나 정확하게 예측했는지 비교할 수 있는 수치로 나타낼 수 있을까? 일반적으로 Accuracy, Precision, Recall, F1 Score 등을 이용해 머신 러닝 모델의 성능을 평가하게 된다.

위 그림은 실제 정답과 머신 러닝 모델의 답을 이용해 만들어 낼 수 있는 경우의 수를 표로 나타낸 것이다. 파란색으로 표시한 a, d는 정답을 맞힌 경우이고 빨간색으로 표시한 b, c는 틀린 경우다.
이 4가지 경우에 대해서 각각 4개의 명칭으로 부를 수 있다.
1) True Positives : 정답이 True인데 모델이 True로 예측한 경우(a의 경우)
2) False Negatives : 정답이 True인데 모델이 잘 못된 답인 False를 예측한 경우 (b의 경우)
3) False Positives : 정답이 False인데 모델이 잘 못된 답인 True를 예측한 경우 (c의 경우)
4) True Negatives : 정답이 False인데 모델이 False로 예측한 경우(d의 경우)

1. Precision
우선 Precision이라고 하는 평가 기준에 대해서 알아보겠다. Precision은 머신 러닝 모델이 True라고 평가한 것들 중에 실제 True인 것의 비율이다.

수식으로 나타내면 위와 같다.

2. Recall
Recall은 '재현율'이라고도 하는 값으로 실제 정답 중에 모델이 맞춘 값의 비율이다.

수식으로 나타내면 위와 같다.

3. Accuracy
Accuracy는 정확도라고도 불린다. 전체 정답 중 몇 개를 맞췄는가에 집중한다.

수식으로 나타내면 위와 같다.
4. F1 Score
위에서 본 Precesion, Recall, Accuracy로 머신 러닝 알고리즘을 평가할 때에 문제가 생길 수 있다.
환자의 의료 정보를 이용해 암 발병 여부를 판단하는 머신 러닝 알고리즘을 학습시켰다고 하자. 실제 데이터 셋에 '암 환자 10명'과 '정상인 990명'의 데이터가 있다고 하자.
만약 머신 러닝 알고리즘이 무조건 '정상인' 판정을 내린다고 했을 때, 이 알고리즘의 Accuracy(정확도) 값은 무려 99%에 달한다. 학습이 전혀 안되었음에도 높은 수준의 Accuracy 값을 갖게 되는 것이다. 이 알고리즘이 좋은 알고리즘이라고 할 수 있을까?
또 다른 예로 일기예보 알고리즘을 설계할 때 무조건 '비가 안 온다'라고 예보했을 경우에도 정확도는 높은 수준을 유지할 것이다.
Precision과 Recall의 경우에도 데이터가 한쪽으로 편향된 경우에 좋은 평가 지표로 사용될 수 없다. 따라서 새로운 평가 지표를 도입할 필요가 있는데, 이래서 나온 게 F1 Score다. F1 Score는 Precision과 Recall을 적절하게 사용한 조화 평균 값이다.
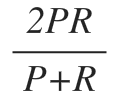
Precision과 Recall을 곱하고 2를 곱한 값을 Precision과 Recall을 더한 값으로 나눈 형태다. 조화 평균을 이용하여 Precision과 Recall 모두 고르게 높은 값을 나타내는 알고리즘이 좋은 알고리즘이라고 평가하게 된다.