출처 : http://it.plusblog.co.kr/221239750876

이전에 봤던 Logistic(로지스틱) Regression의 경우 0과 1을 구별해주는 역할을 했다. 실생활에서는 N개의 선택지 중에 하나로 분류하는 경우도 많이 있다. 주어진 데이터를 N개 중에 하나로 분류하는 머신러닝 알고리즘은 어떻게 만들 수 있을까? Multinomial Classification이 바로 이런 알고리즘이다.
다음과 같은 학습 데이터가 있다고 하자.
x1 | x2 | y |
10 | 5 | A |
9 | 5 | A |
3 | 2 | B |
2 | 4 | B |
11 | 1 | C |
좌표 평면위에 이 것들을 찍어보면 다음과 같다.

어떤 값 (x1, x2)가 주어졌을 때, 그 값이 어떤 클래스로 분류될 것인지 판단할 수 있는 모델을 생각해보자. 일단 단순히 생각해보면 Binary Classification을 이용해서 A, B, C 세 클래스를 구분할 수 있다.
"A or Not"
"B or Not"
"C or Not"
이렇게 3가지 Binary classification을 이용하여 Multinomial classification을 구현할 수 있다.
Hypothesis
우선 두 개의 변수 x1과 x2가 있는 경우 "A or Not"을 판단하는 Binary Classification을 생각해보자.

이를 행렬로 표현하면 다음과 같다.

이런 행렬이 A, B, C를 분류하는 경우 각각에 대해서 하나씩 총 3개가 존재한다. 즉, 한번에 행렬로 표현을 하면 다음과 같다.

결과값을 편의상 다음과 같이 표현하겠다.

이 값은 Linear한 값으로 -INF ~ +INF 사이의 값을 자유롭게 가질 수 있다. Logistic Regression에서 살펴봤듯이 이 값을 0~1 사이 값으로 만들어 줄 필요가 있다. Logistic Regression에서는 이 값을 시그모이드(Sigmoid) 함수를 통과시켜 변형했었다.
배우신 분들이 Multinomial Classification을 위한 새로운 함수를 찾아줬다. 바로 Softmax Function이다. 주어진 가중치 W 값과 X 값을 이용해 결과값을 계산했다고 생각해보자.
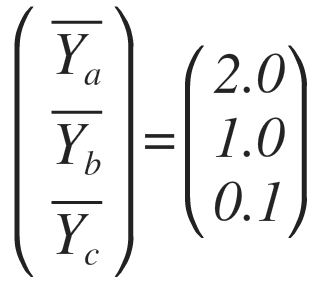
각각 A를 분류하는 Classifier에서 나온 값이 2.0, B에서 나온 값이 1.0, C에서 나온 값이 0.1 이다. 이 때 A일 확률을 다음과 같이 계산할 수 있다.

이 함수를 소프트맥스(softmax) 함수라고 하며, n개의 클래스 중 해당 클래스에 속할 확률, 즉 0~1 사이의 값으로 변환해준다.

앞에서 살펴본 결과값들을 소프트맥스 함수에 넣어보면 해당 클래스가 될 확률값이 나온다.

이 확률값 중 가장 큰 값을 갖는 클래스가 분류될 클래스로 선택되면 된다. One HOT Encoding이라는 기법을 이용하여 하나만 선택할 수 있다. 텐서플로우에서는 argmax라는 기능을 이용하면 된다.
여기까지가 Multinomial classification의 hypothesis 설계이다.
cost function
새로 만들어진 Hypothesis를 이용하여 가중치들을 평가하기 위한 Cost Function도 새로 설계할 필요가 있다. 역시 배우신 분들이 Cost Function까지 멋진걸로 만들어 주셨다.
Multinomial Classification에서는 Cost Function으로 Cross-Entropy라는 것을 이용한다. Cross-Entropy는 다음과 같다.

L은 실제 데이터의 분류 정보이고, S는 Hypothesis를 통해서 얻어진 예측값이다. 이를 다시 써보면 다음과 같다.

이 Cost Function의 -log 값은 다음과 같은 그래프로 그려진다.

일단 매끄러운 모양을 가지고 있으므로 Gradient Descent 알고리즘이 제대로 동작할 것으로 예상된다. 위에서 정의한 Hypothesis는 0~1 값을 갖는다. -log(x)는 입력이 1인경우 0을 리턴하며 입력이 0인경우 무한대 값을 갖게 된다.
위에서 정의한 Cost Function으로 실제 Cost를 계산하는 예제를 생각해보자.

주어진 학습 데이터의 분류다. L1=0, L2=1, L3=0 이다.

우선 우리의 모델이 예측한 값이 정확하게 학습 데이터와 같은 값을 예측했다고 해보자. S1=0, S2=1, S3=0의 값을 갖게 될 것이다. 위에서 정의한 Cost Function에 의하면 이 경우 Cost는 다음과 같이 계산된다.

이 때, L1과 L3의 값은 0이기 때문에 다시 다음과 같이 바꿔 쓸 수 있다.

S2의 값은 1이기 때문에 -log(1)은 0의 값을 갖는다. 즉, 제대로 맞췄을 경우 Cost는 0이다.
다음으로 잘못된 값을 예측했을 경우를 생각해보자.
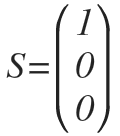
L의 값이 바뀌지 않았으므로 Cost Function은 마찬가지로
이다. S2의 값이 0이기 때문에 -log(0) = INF가 된다. 즉 무한대의 Cost를 갖게 된다.
정답을 맞췄을 경우 Cost가 0이고, 잘못 예상했을 때 무한대의 Cost를 갖게 된다. 실제로 Hypothesis가 내놓는 출력값 S는 0 ~ 1 사이의 값, 즉 확률을 갖게 될 것이다. 따라서 정답이 1인데 예측이 0인 경우는 잘 없을 것이다. (정답인데 절대 정답이 아니라고 예측한 것이니가 무한대의 Cost를 맞아도 싸다)
Gradient Descent
Cost 함수가 -log() 형태로 그려지기 때문에 Gradient Descent 알고리즘이 제대로 동작할 수 있음을 확인할 수 있다. Logistic Regression때와 동일하다.
숙제
모두를 위한 딥러닝 강좌에서 교수님이 숙제를 내주셨다. (- 표시가 하나 빠졌다)

이전 Logistic Regression에서 봤던 Cost Function인 위쪽 수식과 Softmax Classification에서 사용한 아랫쪽 수식이 결국에는 동일한 Cross-entropy라고 한다. 왜 그럴까.

0과 1을 구분짓는 Logistic Regression에서 1일 확률을 y라고 하자. 1이 아닐 확률은 (1-y)가 된다. 이를 p1, p2라고 하겠다. 그러면 수식은 다음과 같이 다시 작성할 수 있다.

H(x)는 Hypothesis가 1이라고 예측할 확률이다. 따라서 0이라고 예측할 확률은 (1-H(x))가 된다. 첫 번째 클래스라고 분류할 가능성을 H(x)라고 할 때, 두 번째 클래스라고 분류할 가능성은 (1-H(x))다.

수식을 다시 써보면,

이렇게 쓸 수 있다. 이를 좀 더 간단히 작성하면,

Cross-Entropy 함수가 되었다. Logistic Regression의 Cost Function도 사실 Cross-Entropy 함수였다.