출처 : http://it.plusblog.co.kr/221238676577

Logistic Regression은 정확도가 높다고 알려진 알고리즘이다. 또 한 Neural Network와 딥러닝을 이루고 있는 중요한 요소 중 하나다. 따라서 딥러닝을 공부하기 전에 Logistic Regression에 대해서 제대로 이해하고 넘어가는 것이 중요하다.
Linear Regression(Classification)에서 결과값은 Linear 한 숫자다. 반면 Logistic regression(Classification)에서 결과값은 특정 분류다. 즉, 어떤 이메일이 스팸메일인지 일반 메일인지 알아보는 경우일 수도 있고, 특정 뉴스를 타임라인에서 숨길 것인지 여부를 알아보는 경우일 수도 있다. 연속된 값을 예측하는 Linear Regression과 다르게 Logistic Regression(Classficiation)에서는 0 또는 1로 표현되는 Discrete 한 값을 예측하는데 사용된다. 이런 종류를 분류(Classification)라고도 한다.
Hypothesis
Linear와 Logistic이라는 이름 차이에서도 알 수 있듯이 Linear Regression에서 사용했던 Hypothesis는 Logistic Regression에서 그대로 사용하기 힘들다.
Logistic Regression에서는 0과 1 사이의 값을 가져야 한다. H(x) = Wx + b라는 Hypothesis는 0 ~ 1 사이가 아닌 -INF ~ INF 값을 갖는다. 따라서 Logistic Regression에 그대로 적용하기엔 무리가 있다. 이 값을 0~1 사이의 값으로 변환해주는 장치가 필요하다. 이 장치로 공부 많이 하신 분들이 찾아낸 함수가 시그모이드(Sigmoid) 함수다.
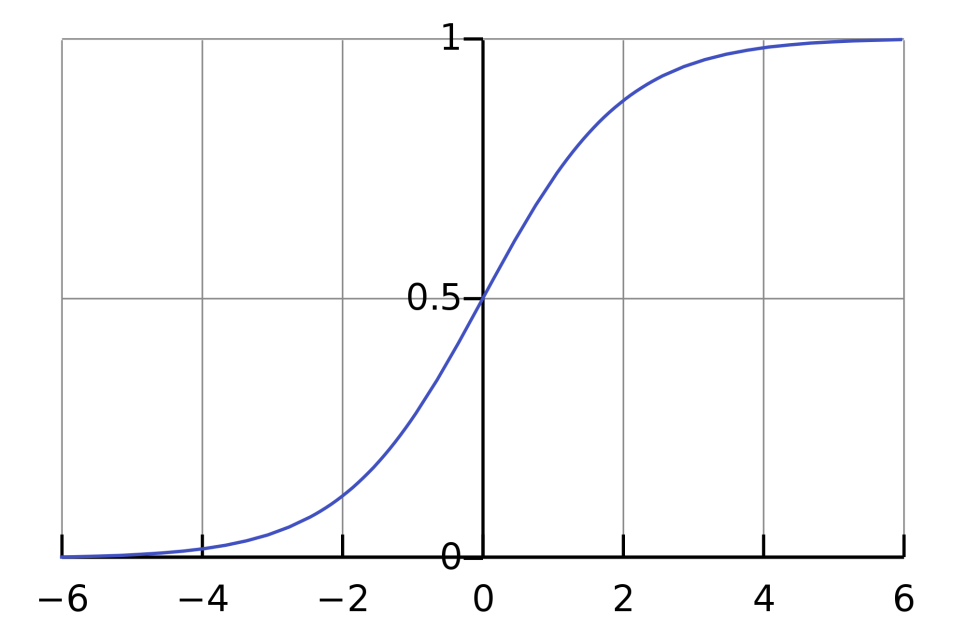
시그모이드(sigmoid) 함수는 X가 0일 때 0.5이며, +INF (양의 무한대)로 갈수록 1에 수렴하고 -INF(음의 무한대)로 갈수록 0에 수렴한다. 즉 H(x) = Wx + b라는 함수의 결과를 시그모이드(sigmoid) 함수에 통과시키면 0 ~ 1 사이의 값으로 만들어 줄 수 있는 것이다.
시그모이드 함수는 다음과 같은 수식을 갖는다.
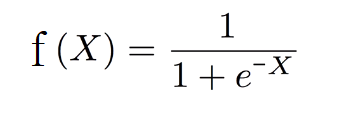
Linear Regression에서 사용했던 Hypothesis를 시그모이드(sigmoid) 함수에 통과시키면 새로운 Hypothesis를 얻을 수 있다.
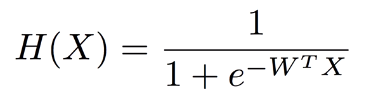
이 Hypothesis는 W에 정의된 가중치에 따라서 0~1 사이에 값을 예측해준다. 이 예측값이 실제 데이터와 얼마나 비슷한지를 나타낼 수 있는 cost function도 재정의가 필요하다는 것을 직관적으로 알 수 있다.
Cost Function
우선 Linear Regression에서 사용한 Cost Function을 그대로 사용하면 어떻게 될까? 가장 단순하게 그냥 사용해보는 케이스를 생각해보자. Linear Regression의 cost function은 다음과 같다.
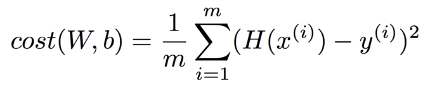
Linear Regression 때와 마찬가지로 W 값에 따라 변하는 cost의 모습을 그려보면 다음과 같다.
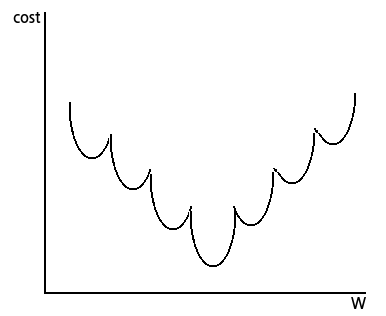
매끈하지 않은 게 보기만 해도 불쾌하다. 이런 Cost Function은 Gradient Descent 알고리즘이 잘 동작하지 않는다. (convex Function이 아니라고 유식하게 말하기도 한다.)
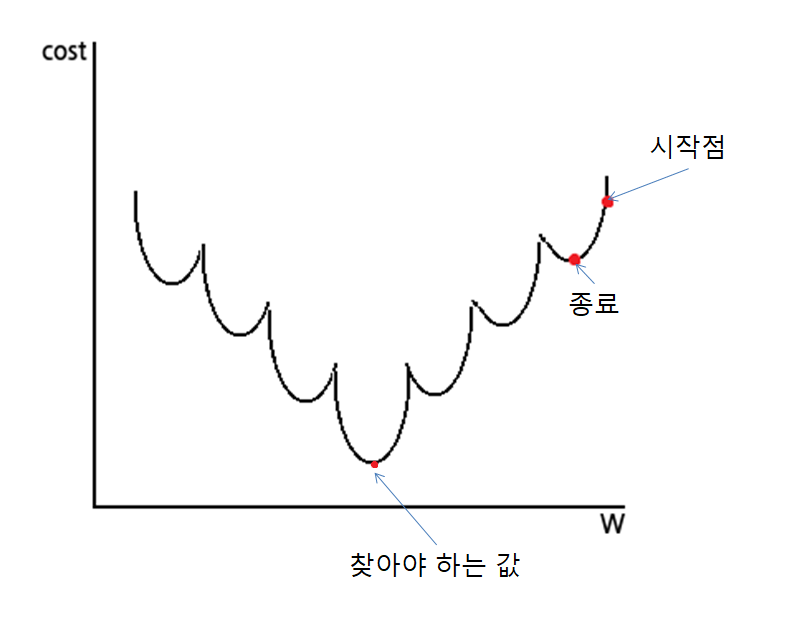
찾아야 하는 값 대신 초기 W 값을 어떻게 잡느냐에 따라 다른 W 값을 얻게 된다. 이런 값을 Local Optima(지역 최적값)이라고 하며 실제로 찾아야 하는 값은 Global Optima(전역 최적값)라고 한다.
Hypothesis를 바꿨으니 그것을 평가하는 Cost Function도 바꿔야 한다. 배우신 분들이 다음과 같은 Cost Function을 제공해주셨다.
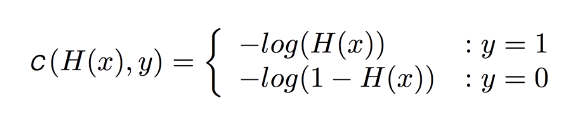
실제 값 y가 0인지 1인지에 따라서 적용하는 Cost가 달라진다. 이 cost 계산 방법을 이용해서 얻어지는 Cost Function은
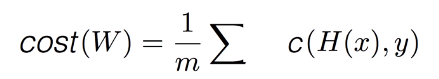
이걸 하나의 식으로 합쳐서
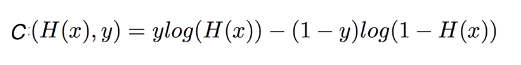
이렇게 표현하기도 한다. y의 값이 0, 1을 가질 수 있으므로 동일한 수식을 한 줄로 표현한 것임을 쉽게 알 수 있다.
이 Cost Function을 그래프로 그려보면
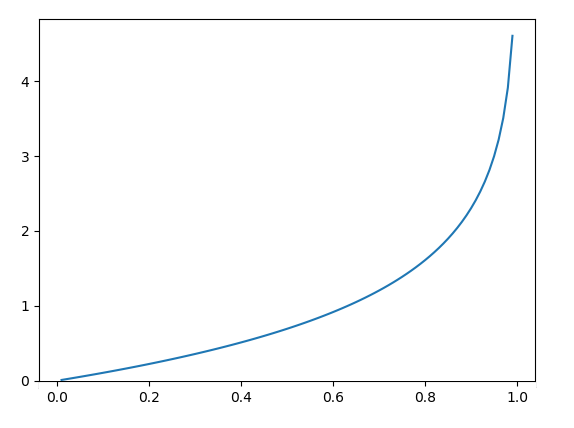
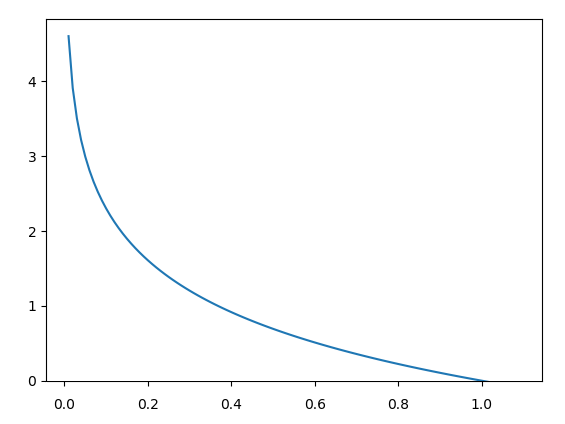
우선 매끄러운 곡선이 나왔다. y가 0이고 Hypothesis가 예측한 값이 0인 경우 cost가 0이다. 반면 y가 0인데 예측값이 1인 경우는 Cost가 무한대로 올라간다. y가 1이고 예측값이 1인 경우는 Cost가 0이고, y가 1인데 예측값이 0인 경우는 cost가 무한대이다. 잘 못 예측하는 경우에 페널티를 주기에 딱 좋다.
Gradient Descent
Cost Function이 정해졌으니 이를 이용하여 평균 cost를 최소화시키는 Gradient Descent 알고리즘을 수행할 수 있다. Cost Function을 가중치 행렬 W에 대한 함수로 표현하면 다음과 같다.
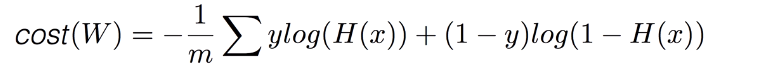
여기에 Linear regression과 마찬가지로 가중치 W에 대한 미분을 취해서 가중치 값들을 개선해나갈 수 있다.
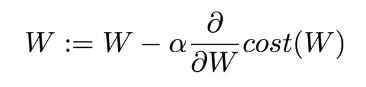
텐서플로우에서는 친절하게도 이런 Gradient Descent 알고리즘을 쉽게 사용할 수 있도록 제공하고 있다.
Hypothesis만 정의해주면 알아서 학습하도록 여러 연산들을 추상화시켜서 제공해준다. 친절한 텐서플로우씨다. 실제 예제 코드는 나중에 작성하고 리뷰해보겠다.