출처 : http://it.plusblog.co.kr/221243267614

머신러닝 알고리즘을 학습시키기 전에 학습 데이터를 조정할 필요가 있을 수 있다. 좀 더 학습이 잘 되도록 입력 데이터를 조정하는 '데이터 전처리(Data Preprocessing)' 과정에 대해서 알아보겠다.
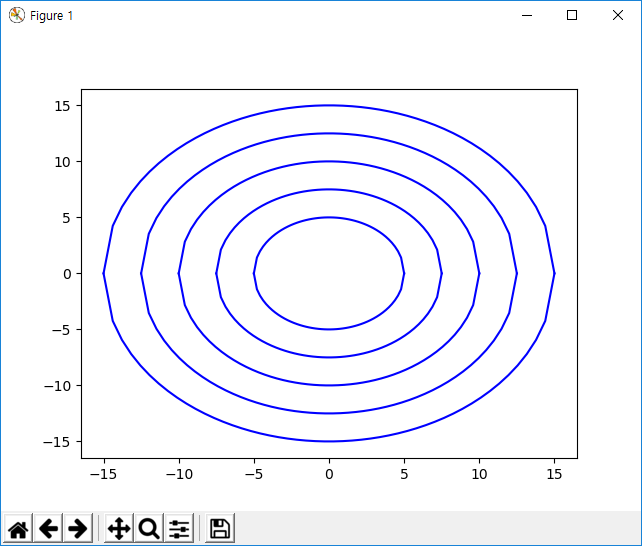
y = w1*x1 + w2x2 + b 라는 모델을 이용하여 학습하는 경우를 살펴보자. 두 개의 입력 값을 이용해서 결과를 예측하는 알고리즘으로 각 입력 값에 대응되는 두 개의 가중치(w1, w2)를 생각해볼 수 있다. 두 개의 가중치를 이용해서 Cost Function을 그려보면 위에서 볼 수 있는 등고선 형태의 그래프를 그릴 수 있다.
x축이 w1, y축이 w2를 나타내며, 가운데로 갈 수록 Cost가 작아지는 형태다.
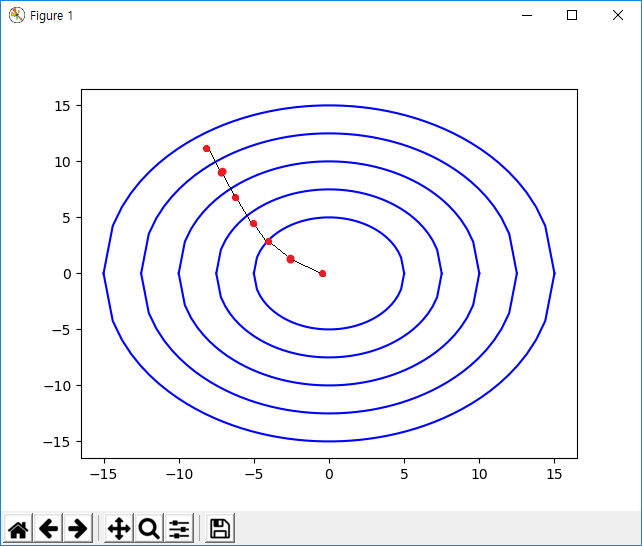
이 경우 Gradient Descent 알고리즘은 이렇게 동작한다. 오목한 부분으로 물이 흘러내리듯이 자연스럽게 최저 Cost 값을 찾아가게 된다. 이상적인 Gradient Descent 알고리즘의 동작이다.
하지만 데이터의 분포가 다음과 같다고 생각해보자.
X1 | X2 | Y |
1 | 8000 | A |
2 | -7000 | A |
4 | 1250 | B |
6 | 10000 | B |
9 | -9000 | C |
학습 데이터의 입력 값인 X1과 X2의 스케일 차이가 확연히 드러난다. 이 경우 가중치(W1, W2 )에 따른 Cost 함수를 등고선 형태로 그려보면
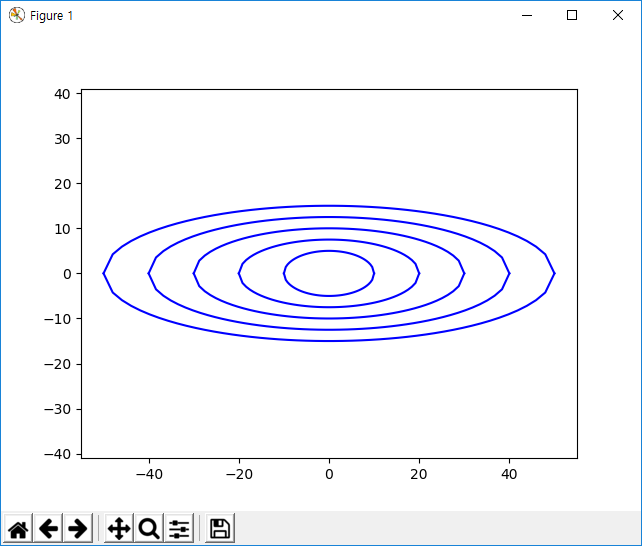
이렇게 찌그러진 모습으로 그려질 것이다.
이런 학습 데이터를 이용해서 Gradient Descent 알고리즘을 돌려보면 제대로 동작할 수도 있지만 두 입력 값의 스케일이 다르기 때문에 Gradient Descent 알고리즘의 Learning Rate가 X1에 대해서는 작고, X2에 대해서는 지나치게 클 수 있다. 이 경우 다음과 같이 동작한다.
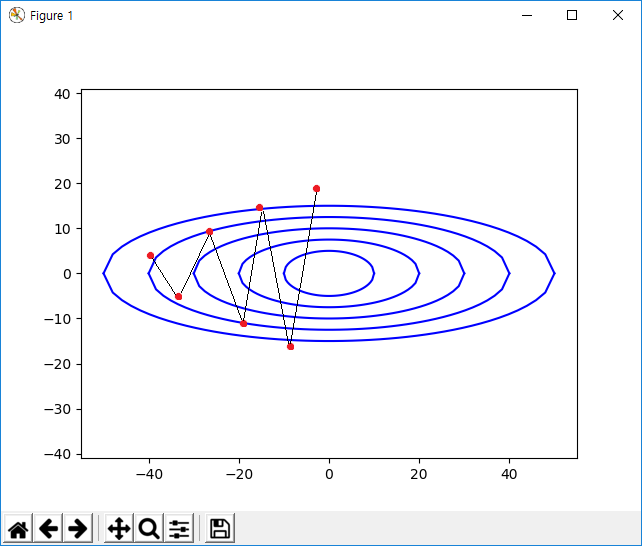
X1 축에 대해서는 수렴하나 X2 축에 대해서는 발산할 수 있다. 그 경우 그래프는 위와 같이 그려진다. 따라서 Learning Rate가 모든 입력에 대해서 같은 스케일로 맞춰주면 좋다. 이런 Gradient Descent 알고리즘의 특성 때문에 데이터의 전처리(Data Preprocessing)가 필요하다.
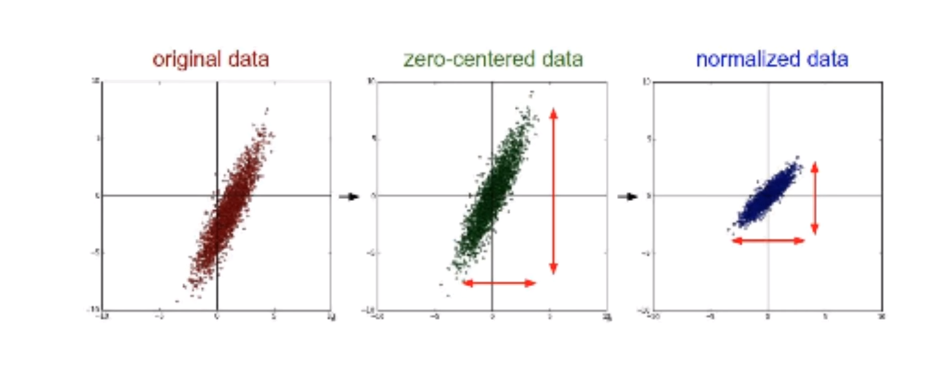
데이터의 전처리는 일반적으로 평균을 0에 맞추는 작업을 우선 거치고, 각 축의 스케일을 맞춰주는 작업을 수행하게 된다.
수식으로 가장 많이 사용되는 방식은 표준화(Standardization)이라고 하는 방법이다.
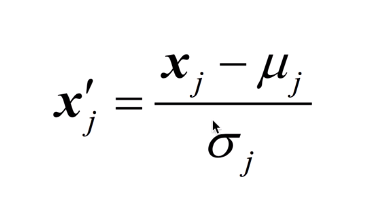
특정 값에서 평균을 빼고, 그 값을 표준 편차로 나눠주는 것이다. 그러면 데이터가 예쁜 형태로 만들어진다.
파이썬 서플로우를 이용한다면 한 줄의 수식으로 표현이 가능하다.
여기까지가 데이터의 전처리가 왜 필요하고 어떻게 전처리를 하면 되는지에 대한 이야기였다.