출처 : http://it.plusblog.co.kr/221243889886

인공지능을 연구하는 사람들의 궁극적인 목표는 우리가 고민해야 하는 골치 아픈 문제들을 인공지능이 대신 생각하게 해주는 것이다. 그렇다면 생각한다는 것에 대한 연구가 먼저 이루어져야 하고 연구자들은 인간의 뇌를 공부하기 시작했다.
인간의 뇌는 아직까지도 완벽하게 연구되지 못 할 정도로 복잡하지만 뇌를 구성하는 기본 단위인 뉴런의 동작 원리는 놀랍게도 단순했다.

인간의 뇌는 기본 단위인 뉴런(Neuron)이 무수히 연결되어 있는 모습을 하고 있다. 뉴런 하나의 모습을 살펴보면 Dendrites라고 하는 부분에서 외부 신호를 수용하고 Axon을 통해 신호를 출력한다. 이런 뉴런이 무수히 많이 연결되어 있는 형태가 인간의 뇌다.
이런 뉴런을 수학적 모델로 다시 그리면 다음과 같다.

뉴런에 있는 각 Dentrites들은 시냅스(Synapse)라고 하는 접점을 통해 외부 뉴런과 연결된다. 뉴런은 입력으로 들어오는 여러 개의 신호들을 하나로 합산한 다음 Activation Function을 통해 자신의 출력으로 만들어 낸다. 만들어낸 출력은 다시 다른 뉴런의 입력으로 들어가게 된다.
이전에 다뤘던 Logistic Regression을 한 번 다시 보자.

입력값의 행렬인 X와 가중치의 행렬인 W를 곱한 값이 있고,

그 값을 시그모이드 함수에 통과시켰다.
이를 뉴런 모델에 적용하면 다음과 같이 그릴 수 있다.

뉴런으로 들어오는 입력들을 X라고 하는 행렬에 표현하고 각 입력에 해당하는 가중치를 W 행렬에 표현한다. 두 행렬을 곱한 값이 Cell body에서 수행하는 작업이며, 이 값에 시그모이드 함수를 적용한 값이 이 뉴런의 최종 출력값이 된다.

Multinomial Classification은 Logistic Regression 모델을 N 개 적용한 것과 같으므로 위 그림처럼 그릴 수 있게 된다. 이런 뉴런이 서로 복잡하게 얽혀있는 모습은 다음과 같이 그려볼 수 있다.
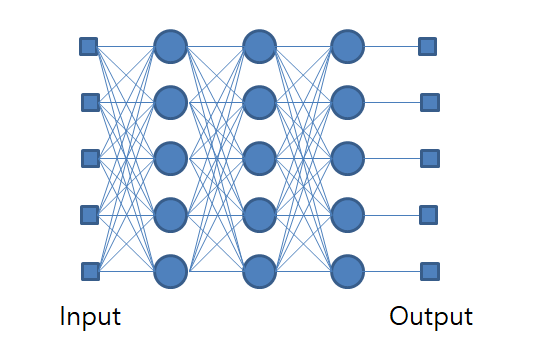
각 뉴런들이 복잡하게 연결되어 있고 각 연결마다 가중치가 존재하게 된다. 이런 뉴런들의 복잡한 연결을 뉴럴 네트워크(Neural Network)라고 하며 딥러닝의 원래 이름이라고 할 수 있다.
머신 러닝 모델과 XOR 문제
머신 러닝 초기 연구진들은 인공지능에 대해 생각하면서 X1과 X2를 입력받아 Y를 출력하는 일종의 논리 게이트를 만들어 복잡하게 연결하면 인간처럼 논리적 사고를 할 수 있을 거라고 생각했다.

두 개의 입력 값을 받아서 새로운 결론을 도출해내는 모델을 생각해냈다. AND 연산과 OR 연산은 Linear 한 모델 하나로 분리가 가능했다.

두 개의 입력 X1과 X2가 0, 1의 값을 가질 수 있을 때, OR 연산과 AND 연산은 하나의 직선으로 표현이 가능했다.

문제는 XOR였다. 머신 러닝을 연구하는 연구진들은 이 XOR 문제를 간단한 모델로 풀 수 있는지를 고민했다. 그러다가 MIT AI Lab의 Marvin Minsky라고 하는 교수가 하나의 모델을 이용하여 XOR 문제를 풀 수 없다는 것을 수학적으로 증명해 버렸다. 간단한 모델로 풀 수 없음이 증명된 것이다.
Multi Layer Perceptron
이어 하나의 모델이 아닌 하나 이상의 레이어(Layer)를 갖는 MLP(Multi Layer Perceptrons, Multi Layer Neural Nets)를 이용하여 XOR 문제를 해결할 수 있음을 제시했다. 저런 모델을 여러 개 이어 붙여서 XOR을 구현할 수 있음을 제시한 것이다.
하지만 더 큰 문제는 이 여러 레이어(Layer)를 갖는 Multi Layer Perceptron을 학습시킬 방법이 없었다는 것이다. 여러 레이어에 걸쳐 연결된 Perceptron 사이의 가중치를 데이터를 통해 학습 시킬 방법이 당시에는 알려져 있지 않았다. Marvin Minsky 교수는 실망한 나머지 자신의 책을 통해 Multi Layer Perceptron을 학습 시킬 방법은 존재하지 않는다고 발표해버린다. 이 책을 읽고 많은 연구진은 Neural Network에 대한 관심을 잃게 된다.
Backpropagation
그러다가 1974년, 1982년 Paul Werbos라는 연구자와 1986년 Hinton이라는 사람에 의해 Backpropagation이라는 알고리즘이 고안되었다.

기존 Neural Network의 큰 문제는 Input에서 Output 쪽으로 값이 전파되기 때문에 최종적으로 Output 값이 실제와 달랐을 때 앞쪽에 있었던 Layer의 가중치를 조절하기가 힘들다는데에 있었다.

Backpropagation 알고리즘의 원리는 간단하다. Forward propagation으로 예측한 결과 값이 틀린 경우, 그 에러를 다시 반대 방향으로 전파시켜가면서 가중치 W 값을 보정해나가는 개념이다.
이러한 개념을 1974년 Paul Werbos가 자신의 박사 논문에 추가했다. 이후 1982년도 다시 논문을 발표했지만 이미 식어버린 관심을 살릴 수는 없었다. 이후 Paul Werbos와는 독립적으로 Hinton이라는 사람이 1986년에 같은 개념을 소개하는 논문을 발표하게 되었고, 조금씩 사람들의 관심을 받기 시작했다.
또 LeCun이라는 교수에 의해 수행된 고양이 실험에서 특정 모양에 대해서 특정 뉴런만 반응한다는 것을 알게 되었다. 일부 신경들의 그림의 부분부분들을 담당하고 그것들이 나중에 조합되는 것이 아닐까 하는 생각을 이용해서 'Convolutional Neural Networks'라고 하는 알고리즘을 개발해냈다. 우리가 잘 알고 있는 알파고 역시 CNN 알고리즘을 사용했었다.
이미지의 일부분을 잘라서 입력으로 주고 나중에 다시 합치는 방법인 CNN은 글자 인식 등의 부분에서 높은 성능을 발휘했다. 인식률이 90%에 달할 정도로 높은 성능을 보여줬다. 이후 CNN 알고리즘은 자동주행 차량 연구에도 사용되었다.
학습 성능 문제
하지만 새로운 문제에 봉착했다. Backpropagation 알고리즘을 학습할 때, Neural Network의 Layer 수가 많아질수록 성능이 나빠졌다. output 쪽의 에러를 input 쪽으로 전파해야 하는데, Layer가 많아질수록 input 쪽에 있는 앞단에 에러가 전파되지 않는 문제가 생겼다.

실제로는 모든 노드의 가중치를 적절하게 조정해야 하지만 Backpropagation으로 전파되는 에러의 흔적이 Layer를 거듭할수록 옅어져 input Layer 쪽에서는 거의 변동이 없게 되는 것이다. 실제로는 입력 쪽 Layer의 가중치가 더 중요한데 에러가 잘 전파되지 않아 성능 향상이 어려워진 것이다.
Neural Network가 이렇게 어려움을 겪고 있는 사이 다른 머신 러닝 알고리즘이 두각을 나타내기 시작했다. SVM, RandomForest 등의 알고리즘이 소개되었다. 이런 알고리즘은 Neural Network보다 간단하고 이해하기 쉬우면서 성능도 준수해서 더욱더 주목을 받을 수 있었다.
이에 1995년 CNN을 고안한 LeCun 교수조차도 SVM이나 RandomForest 같은 알고리즘이 더 간단하고 더 성능이 좋게 나온다고 말을 했다. 여기서 딥러닝의 2차 침체기가 도래했다.