출처 : http://it.plusblog.co.kr/221248822124

지난 포스트에서 여러 유닛으로 구성된 신경망(뉴럴 네트워크, Neural Network)을 이용하여 XOR 문제를 풀어봤다. 특정 가중치 W와 Bias들을 이용하면 XOR처럼 동작하는 모델을 만들 수 있음을 알아봤다.
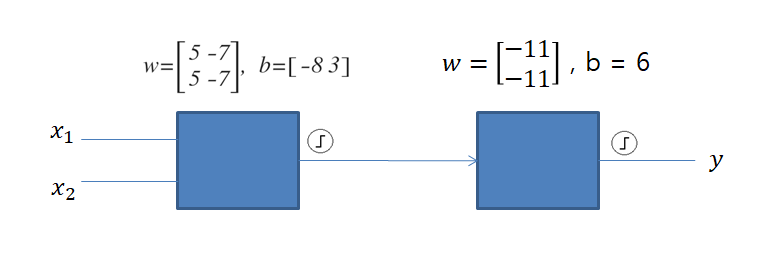
이제 문제는 XOR처럼 동작하는 가중치 W와 Bias를 어떻게 찾아갈 것인가로 넘어갔다.
여러 레이어로 구성된 신경망을 학습하는 딥러닝(Deep Learning)은 Backpropagation이라고 하는 알고리즘을 사용한다. 1974, 1982년 Paul Werbos와 1986 Hinton에 의해 발견된 알고리즘으로 결과값의 오류를 다시 이전 레이어로 전파하는 방식의 알고리즘이다.
이 Backpropagation에서 가장 중요한 법칙은 편미분의 Chain Rule이다. Chain rule은 다음과 같다.
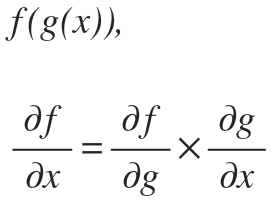
두 개의 함수 f와 g가 있고 이것들로 이뤄진 복합함수에 대해 편미분을 구하면 위 공식과 같이 Chain rule이 성립한다.
다음과 같은 신경망(뉴럴네트워크, Neural Network)을 생각해보자.
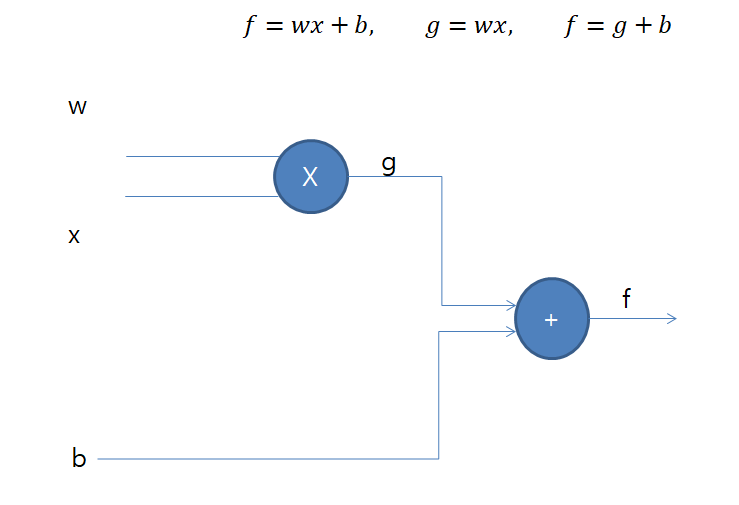
f=wx+b 라는 함수가 있을 때, 위 그림처럼 신경망을 그려볼 수 있다. 이 때, g=wx라는 또 다른 함수로 만들어보면 f=g+b라는 복합함수로 생각해볼 수 있다.
이 신경망을 학습시키기 위해서는 각 w, x, b가 결과값인 f에 미치는 영향도를 알아야 한다. 즉, f라는 결과값을 각 입력 값인 w, x, b 값으로 미분한 값을 알아야 한다.
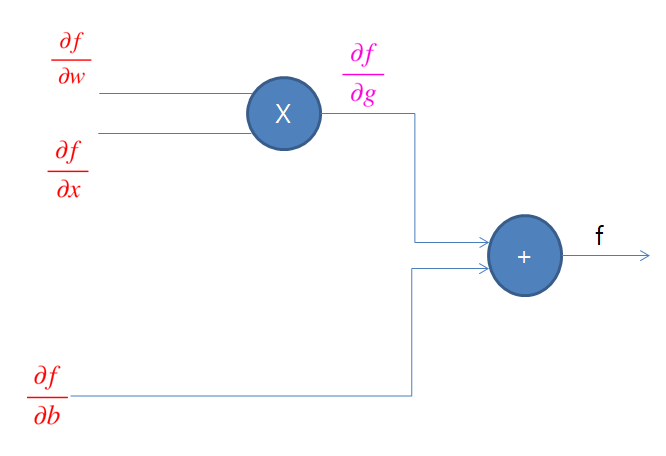
다시 말해서 위와 같은 신경망에서 결과값 f가 있을 때, 입력값 w, x, b에 대한 편미분 값을 알아야 한다. 이 때, 위에서 봤던 Chain Rule을 이용해서 w, x로 편미분한 값을 얻어올 수 있다.
위 식에서 각각 입력에 대한 편미분은 다음과 같이 구할 수 있다.
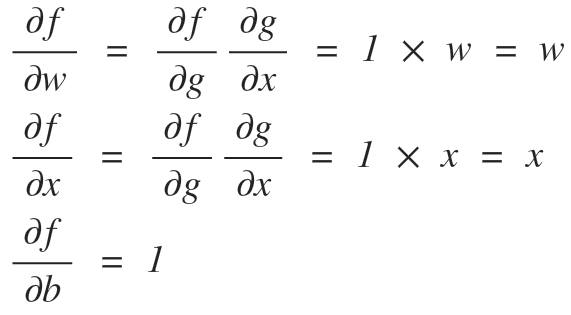
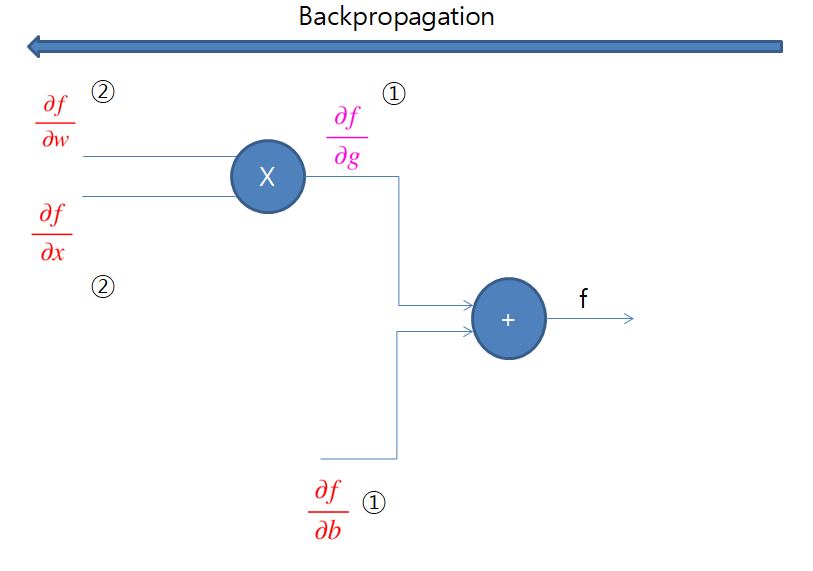
Backpropagation은 이렇듯 편미분의 Chain rule을 이용하여 뒤에서부터 편미분 값을 구해나가는 방식으로 '뒤에서 앞쪽으로' 전파되는 계산 알고리즘을 사용한다. Backpropagation을 이용하면 각 입력단마다 최종 결과값에 미치는 영향도인 편미분 값을 구할 수 있게 된다.
이 편미분 값이 어디에 이용되느냐. 각 노드의 가중치 값을 결정하는 Gradient Descent 알고리즘을 떠올려보자.
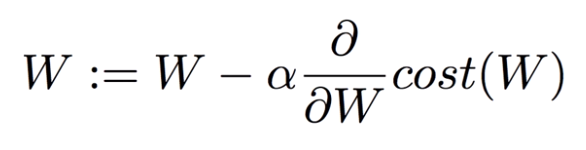
가준치 W에 대해서 Cost 함수를 미분한 값을 이용해 다음 W 값을 조정해나갔다. 마찬가지로 딥러닝에서 최종 출력 노드의 Cost 함수에 중간 가중치들이 어떤 영향을 미치는지 Backpropagation을 이용해 미분값을 구하고, Learning Rate를 이용해 다음 값을 조금씩 조정해서 최적의 가중치 값을 찾아나가는 것이다.
여기까지 설명한 내용이 Backpropagation의 기본적인 개념이었다.